关于数据库操作和管理的文章,网上文章非常多,但对于数据库系统的工作方式却少有文章介绍。本文将以关系型数据库为主展开,并采用开源的MySQL以及存储引擎InnoDB,对数据库系统的基本工作方式和一些性能考虑因素进行介绍,而对于数据库设计原理,如何实现,以及如何操作和管理数据库等不做展开说明。
原创文章版权归原作者所有,商业转载请联系原作者获取授权,任何转载请注明来源:https://xupifu.github.io/2017/01/01/how-db-work/
1 数据库定义
A database is an organized collection of data. It is the collection of schemas, tables, queries, reports, views, and other objects. The data are typically organized to model aspects of reality in a way that supports processes requiring information, such as modelling the availability of rooms in hotels in a way that supports finding a hotel with vacancies.
A database management system (DBMS) is a computer software application that interacts with the user, other applications, and the database itself to capture and analyze data. A general-purpose DBMS is designed to allow the definition, creation, querying, update, and administration of databases. Well-known DBMSs include MySQL, PostgreSQL, MongoDB, MariaDB, Microsoft SQL Server, Oracle, Sybase, SAP HANA, and IBM DB2. A database is not generally portable across different DBMSs, but different DBMS can interoperate by using standards such as SQL and ODBC or JDBC to allow a single application to work with more than one DBMS. Database management systems are often classified according to the database model that they support; the most popular database systems since the 1980s have all supported the relational model as represented by the SQL language. Sometimes a DBMS is loosely referred to as a
database.
简而言之,数据库是一堆信息数据的集合,并且通常会提供一种访问模型用来操作相关的信息数据。而DBMS,即数据库管理系统,是数据库模型的具体软件实现,常见的DBMS有MySQL,Microsoft SQL Server,Oracle,MongoDB等。由于实现时各个系统的访问接口可能存在差异,因此出现了一些标准化接口,如SQL,ODBC,JDBC等,可以让同一个用户程序使用多个不同的DBMS。目前,最流行的数据库模型为关系型数据库。
通常,数据库结构都可以抽象为一张张的表(table),有表头(heading),对应为列属性(column attribute),每个列属性又包含有名称(attribute name),类型(type name)和长度(length),每行的数据体,也称为元组(tuple),即为一条数据记录。数据库需要提供基本的操作方法包括:查找(query),插入(insert),删除(delete),更新(update)等。关系型数据库是第一个采用数学的形式化表达的数据库,它增加了表与表之间的约束,随之也增加了数据库操作的复杂度,即操作某条记录可能需要操作多张表,比如query操作,就可能需要多张表join才能合成用户需要的记录。不过,由于其数学上的严格保证,使得该模型成为了主流的数据库模型,当然,近些年的NoSQL模型的数据库发展也非常迅猛,其高性能的优点使得该类型的数据库在一些领域大放异彩。
本文将以关系型数据库为主展开,并采用开源的MySQL以及存储引擎InnoDB为例进行说明,NoSQL模型的数据库不在此文中介绍。需要声明的是,本文旨在介绍数据库系统的基本工作方式和一些性能考虑因素,不展开说明数据库设计原理,如何实现,以及如何操作和管理数据库等。在本文展开之前,这里先提出几个数据库问题:
- 性能:对于数据库系统,除了提供基本功能外,还要考虑性能,尤其在数据集比较庞大的情况下。如何组织及操作这些数据记录就变得格外重要,DBMS经常使用的数据结构有如B树,B+树,Hash链表,LRU链表等,同时,会引入事务,索引,缓存,并发控制等技术。
- 事务:对于数据库系统,一般有ACID(Atomicity,Consistency,Isolation,Durability)四项基本特性,事务(transaction)指一个或一组指令的集合,它要么全部执行成功,要么全部失败,它是实现ACID特性的一种方法。
- 碎片:无论是数据库记录,还是文件,在设备上的存储方式都取决于设备本身及上层管理,通常,都存在一个最小的读写粒度,比如4KB。对于一条记录或一个文件,大小可能远远小于这个最小粒度,但存取时却必须按最小粒度,所以不可避免的就造成了空间上的浪费。相比之下,一条数据库记录的大小通常可能为几十或几百字节,空间碎片问题会更加明显,这也成了数据库系统要着重解决的问题之一。
- 其他:数据库系统还有很多主题,比如复制,备份,恢复等等,本文不做展开。
2 数据库基本架构
下图为MySQL架构图,大部分数据库的基本架构部件是类似的,只是名称或组织方式存在差异。
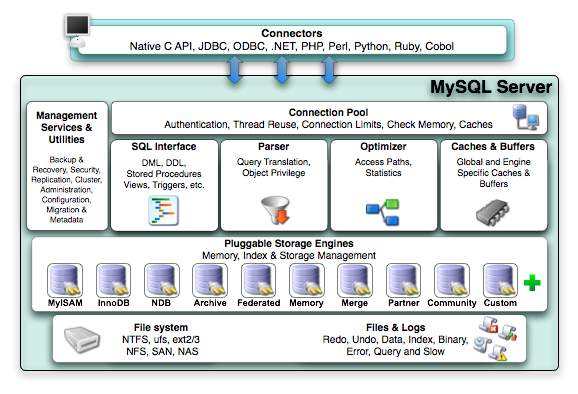
- Connection管理:对应为Connection Pool,用于处理客户端连接,授权认证,安全等
- Query管理:一般包含SQL相关接口,包含解析,优化等
- Cache管理:主要用于缓存数据记录,索引等
- Log管理:日志相关管理,一般属于存储引擎(Storage Engines)的一部分
- 数据访问管理:用于数据组织,索引处理,IO管理等,属于存储引擎的一部分
- …
MySQL能够支持的存储引擎非常多,基于性能和安全可靠性的权衡,目前业界使用最多的存储引擎InnoDB。
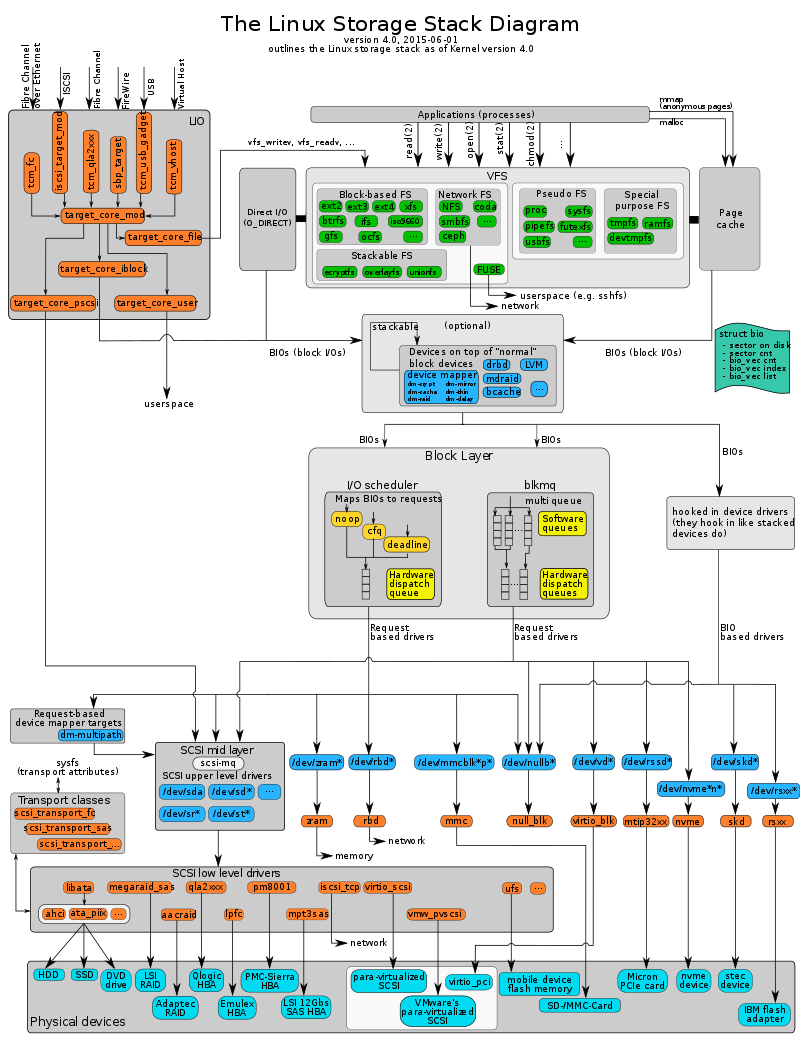
数据库是对数据信息记录集合的管理,文件系统是对文件管理,文件本身也是数据集合,两者本质上非常相似,尤其是Linux的VFS(Virtual File System)架构,如下图所示,对外有统一的系统调用API,用于处理用户程序访问,有Page Cache,VFS之下是一个个具体的文件系统(类比为存储引擎),带有日志功能的文件系统还要自己进行日志(Log)管理。
3 数据库访问模式
3.1 查询
针对单张数据表的查询,主要包括单行查询,范围查询,全表查询,行ID查询等,如果跨越多张表,则还涉及join查询。一个查询经过Query管理器相关优化后,会向Cache管理器索取数据,如果Cache Miss,则通过底层数据访问管理器发起IO请求。为加速查询,数据记录的组织通常采用索引技术,在数据读取上,采用预读取(预测位置或顺序预读)到Cache的方式等等。存储介质上,早期主要使用机械硬盘,随机存取性能较差,后来的SATA SSD在一定程度上弥补了这一缺陷。不过,IO性能一直以来都是整个系统的主要瓶颈所在。数据库系统针对底层的存储设备进行了专门的优化和设计,以便把随机IO尽可能转成顺序IO(B+树,事务日志技术等)。当然,存储设备本身也在不断发展,从机械硬盘到SATA SSD,再到近些年的NVMe SSD,设备性能提升迅猛,原来的IO性能瓶颈逐渐减弱,应用或CPU的性能瓶颈则逐步突显。
提高查询性能的主要途径包括:
- 语句:查询语句设计和优化
- 索引:适当建立索引,优化数据组织方式,尽可能将访问转化为顺序IO
- 缓存:开辟较大的缓存区域(热点数据缓存以及写缓冲),配合预读取技术,减少IO带来的影响
- 设备:使用性能更高的存储设备(同时兼顾可靠性)
这里潜在的引入了一个问题:在提高性能方面,增加缓存(内存)和更换高速存储设备,哪个带来的效益会更高?这点需要评估和权衡。
【蚍蜉】注:Jim Gray和G. F. Putzolu在八十年代提出了”Five Minutes Rule”(后来进行一定修正),它用来决定一个数据应该放在内存中还是在外存上(按需读进内存),是一个基于成本和性能权衡考虑的规则。规则大意是:当一个数据每5分钟就至少被访问一次,那么应该将数据放在内存中,否则就放在外存上。业务系统可以自行统计有多少数据具有这样的特性,据而决定内存的大小。5分钟只是一个典型值,实际值取决于业务本身。近几年,NVMe SSD的发展,极大的弥补了内存和硬盘之间的性能差距,它可以用来作为缓存(和内存一起),也可以作为外存使用,随机性能表现得也非常好,因此,该规则可能面临重新定义。
3.2 写
数据库写主要包含插入(insert),删除(delete),更新(update)等,一般都需要从存储设备中读取相对应的页到内存,然后修改数据行,最后刷回到存储设备上,何时刷回则取决于相应的管理算法。一般,这个缓冲与上文查询一节中提及的缓存是同一个。
由于记录大小通常都小于最小读写粒度,如果一次写入数据就立刻刷回到设备上,对于底层设备,性能和寿命要求就会比较高。但如果缓存大量脏数据,数据丢失带来的影响又比较大,为了权衡这两方面的影响,事务日志技术就被提出,除了用来保证ACID特性外,还能极大化利用IO性能,提高数据库系统的性能和可靠性。事务日志只需记录日志,顺序追加写入,数据页还可以继续保留在缓存中,直到合适的刷回时机到来,它至少带来了两个好处:
- 延缓IO写入,合并IO,从而减少了IO写入
- 事务日志可以顺序写入,只需要小段的顺序存储空间,从而将原来的随机IO转化为顺序IO
注意,一次写请求包含多次写:日志写和数据写。为保证正确性和完整性,一般还会启用双写缓冲(Double Write Buffer),这又会再增加一次数据写。
大多数DBMS,在使用事务日志技术时,都遵循WAL协议(Write-Ahead Logging Protocol),主要规则如下:
- 每一个事务,事务日志必须先于数据记录写入存储设备
- 事务日志必须严格按照顺序写入,先生成的事务日志必须先写入
- 先记录commit命令的日志,后完成事务的commit请求
一般的写过程如下:
- 在日志缓冲区中,记录事务开始标志
- 在日志缓冲区中,记录写命令
- 在数据缓冲区中,写入相应数据(如写入对应的页不在缓冲区,则需先读入)
- 在日志缓冲区中,记录事务commit标志
- 将日志缓冲区对应的日志页,顺序同步写入到日志文件(存储设备)中
- 根据时机,将相应的脏数据页写入到存储设备中(延迟写入)
事务日志一般都设置有checkpoint点,目的是刷回已写入日志对应的脏数据页,降低日志与数据的不一致程度,同时,checkpoint操作会被记录到日志中,它就像一个存档点,当需要恢复时,检查checkpoint点,并进行恢复,点的间隔越短,恢复时间也越少(同时,占用的IO也越多,会影响正常的IO,需要权衡)。另外,缓冲区有自己的替换策略和脏页回写策略,用来回收一些数据页,以使缓冲区一直保持有可用的空闲页。
3.3 IO
由上文可知,IO请求主要分为两种:
- 数据页请求:查询或脏页回写的时候提交相应的读写请求,通常为随机IO(数据记录+索引,同步读,异步写)
- 日志页请求:数据库需恢复时读取,正常情况下只有日志文件的写请求,根据日志缓冲区的管理进行回写,通常为顺序IO(同步写)
数据页和日志页都需要经过缓存管理器,数据访问管理一般都可以控制IO是否要经过操作系统的缓存区(OS Cache),比如在innodb存储引擎中,就至少提供了两种刷回方式,SYNC方式和DIRECT-IO方式。日志页缓冲回写策略相对复杂(可见上文的写过程),一般可以有以下几种控制方式:
- 按commit命令语义,每次将日志页持久化到日志文件中
- 保留在日志缓冲区,按一定的时间间隔持久化到日志文件中
- 保留在日志缓冲区,暂不刷回,待日志页积累到一定程度,或者有其他条件(checkpoint等)时持久化
- 写到日志文件,但日志文件保存在OS Cache中,实际刷回由OS决定,或者数据库系统显式SYNC日志文件
无论那种请求,对存储设备的存取能力都有一定的要求,同时需要优先照顾日志页请求。在数据库系统中,通常都会获知底层设备的存取能力,并以此派发一定数量的IO线程,控制IO请求的提交速度。
另外,值得一提的是,随着负载的增加,当IO成为瓶颈后,数据库系统并不一定会进入一个性能稳定状态,相反,可能会出现性能下降或波动较大的情况。原因何在呢?通常数据库都存在冷热数据之分,正常情况下的数据写都是异步的,并不会产生较大性能波动。但是,当发生热数据需要从存储设备读取时,可能就存在多个线程/连接在同步等待的情况,等待时间就会较长,如果其中有写请求,等待的时间可能就更长,而这带来的可能是雪崩式的效应,后续的请求就得一直等待直到获得处理机会。解决此类问题的策略之一为读写分离(需要注意对一致性的要求程度)。
结合以上缓存等的描述,可以看到,受限于IO能力,数据库系统的一个主要优化方向便是,如何将小粒度的随机读写IO转化成大粒度的顺序IO,但这个优化策略主要基于传统磁盘,对于SSD之类的设备,该策略就不见得依然适用了。
3.4 碎片
我们知道,一条数据库记录通常都小于底层的最小读写粒度,而数据库系统本身也有自己的页面管理,该页面通常都大于底层最小读写粒度,常见的有4K,8K,16K等。这就意味着,要读取一条数据库记录,就需要读取整个页面,而页面内部可能存在大量对此时任务无关的数据,而写入也是类似,可能仅修改了页面的一小部分,却需要整页进行回写。同时,数据库管理还存在大量索引数据(B/B+树组织),碎片也大量存在,为定位一条记录位置,不可避免的存在随机访问。
可能的碎片包括:
- 行碎片:一条数据记录被分成多个片段,存储在多个地方,有些存储引擎存在这样的碎片数据,innodb一般不会出现该类碎片
- 行间碎片:逻辑上顺序的数据记录/数据页,在存储介质上不是顺序存储的,对于范围查询或全表查询等可能造成较大影响
- 页面碎片:读取的页中有用数据记录可能较少,造成了内存浪费,读写时也会造成底层存储设备的带宽浪费(可以评估一下读写被放大了多少,另外blob类型的变长数据也会造成页面碎片和空间浪费)
对于前两种碎片,存储引擎可以通过重建索引,重排数据或数据结构优化进行一定的优化处理。针对第三种,目前暂未有存储引擎对此进行处理,数据库进行架构部署时,一般采用了诸如Memcached等进行架构层面的优化处理,很大程度上缓解了第三类碎片的问题。当然,随着NVMe SSD这种随机性能比较高的存储设备的出现,碎片问题可能需要重新考虑,这个问题与前文提及的问题:到底是增加内存,还是更换高速存储设备?有一定的重合,都需要进行评估。
另外,如果页面粒度大于底层设备的读写粒度,一个页面的原子性写入及完整性保证就需要重点考虑,以免破坏原有数据,这个问题有的是在文件系统层面解决,有的需要数据库系统自己解决,如上文提到的Double Write Buffer即是解决该问题的一种方法。
3.5 并发
并发控制是一个非常庞杂的话题,本文无法过多展开,仅根据数据库架构做简单说明。
从上文数据库系统的基本架构中可以看到,并发控制无处不在:客户端/网络连接处理,表/记录操作,缓存管理,IO请求调度等等,每一项任务都需要有对应的线程/进程(下文统称为线程)进行处理。实践显示,在各个操作系统中,创建的线程消耗虽然并不昂贵,但在需要常用的场景中,不断的创建和销毁线程却是不必要,通常只需要维护一个线程池(thread pool)即可,有任务时,从池中选取一个线程对任务进行处理。
最理想的情况是,各个线程之间的处理都是独立的,但实际上,线程之间总有一些共享资源/数据结构的竞争,在数据库系统中,可以表现为表,记录,事务,日志,索引,缓存等,为了保证正确性,这些资源需要用各种锁加以保护,比如原子变量,互斥锁,读写锁等,对应到资源有表级锁,行级锁,保护事务的两阶段锁(Two-Phase Locking)等。锁的粒度一定程度上决定了线程可并行的程度,粒度越细,需要同步等待的概率越低,但实现的成本也越高;粒度越粗(有些系统甚至使用了全局互斥锁),实现简单,但线程阻塞的概率也越高,整体系统也会受到极大影响。
多核多线程能够一定程度上提高系统的性能,但由于各种资源之间的竞争,使得在核数增加的情况下,整体性能并无法相对线性提高。为了更好的提高并发性能,一些无锁化数据结构也在不断的研究并应用到并发程序中。
4 MySQL性能优化参数
本章将根据上文所述的数据库访问模式,介绍MySQL数据库相关的性能优化参数,存储引擎基于主流的InnoDB,MySQL版本为5.6。
4.1 系统级约束和建议
- 操作系统:对于高并发业务应用,不建议使用Windows,可选Solaris,Redhat,CentOS和Oracle Linux等,内存分配算法库可用tcmalloc等
- 资源上限:开放文件数和进程数等系统资源的限制
- 页面回收:在配置缓存大小时,注意不要触发系统的页面回收机制,页面的换进换出会使性能受较大影响
- 文件系统:根据评测和使用经验,建议使用XFS,也可使用ext3/4,mount文件系统时可加入选项”noatime,nodiratime,nobarrier”,关闭一些无用功能
- IO调度器:在Linux下,可自选IO调度器(CFQ,AS,DEADLINE,NOOP),如传统SSD可用NOOP调度器,NVMe SSD采用默认即可
4.2 缓存控制
- 缓存大小:innodb_buffer_pool_size,除了操作系统,其他程序,数据库系统等必须使用的内存外,剩余内存一般均可用于缓存,但必须注意确保余量,避免触发系统的页面回收,否则性能将受较大影响
- 缓存实例:innodb_buffer_pool_instances,将整个缓存分成多份进行管理,用于细化锁粒度(如LRU链表锁),默认8个
- 刷回方式:innodb_flush_method,建议使用DIRECT-IO方式,绕过OS Cache
- 脏页比例:innodb_max_dirty_pages_pct,最大的脏页比例,需要配合设备能力,将脏页控制在一定的比例范围内,默认75%
- 双写缓冲:innodb_doublewrite,除了明确知道对于写完整性要求不高,或者底层文件系统/设备有额外支持外,该参数需开启(ON)
- 邻近刷回:innodb_flush_neighbors,InnoDB在脏页刷回时会将临近的脏页一并刷出,这样可以将随机IO转化成顺序IO,当然,可能会存在重复刷回的问题,对于磁盘而言,开销是值得的。但是对于SSD,运行时的随机IO与顺序IO并没有明显的差距,可以关闭该功能
4.3 日志管理
- 日志文件大小:innodb_log_file_size,根据业务情况进行设置,对于高性能业务,尤其写需求较多的业务,需要设置较高的值,不过,值越高,崩溃后的恢复时间也越长
- 日志文件数量:innodb_log_files_in_group,轮换用的日志文件个数,通常2个即可
- 日志缓冲大小:innodb_log_buffer_size,一般默认值已经够用,实际运行时可查看innodb_log_waits状态变量,如果非0,可增加该缓冲大小
- 日志缓冲刷回:innodb_flush_log_at_trx_commit,0表示保留在内存中,不主动持久化到日志文件,性能最好,安全性最差,1表示每次commit必须持久化到日志文件,安全性最好,性能最差,2表示保留在内存,但每秒进行一次持久化,为折衷选择,通常可设置为2
- 日志刷回频率:innodb_flush_log_at_timeout,默认周期为1秒
- 日志文件路径:innodb_log_group_home_dir,为了避免数据写和日志写之间的相互影响,会将日志文件放到不同的设备上,可以修改日志文件路径
4.4 IO控制
- 页面粒度:innodb_page_size,默认为16K,根据业务情况及设备支持进行调整
- 设备能力:innodb_io_capacity,设置设备存取能力,默认为200 IOPS(主要针对磁盘),对于SSD类型设备,根据设备能力进行设置
- 读线程数:innodb_read_io_threads,默认为4
- 写线程数:innodb_write_io_threads,默认为4
4.5 并发控制
- 最大连接数:max_connections,根据业务情况进行调整,需要配合系统级的资源上限设置
5 数据库测评
…
6 附录
- Architecture of a Database System
- How Does a Relational Database Work
- Wikipedia: Virtual File System
- Wikipedia: Five Minute Rule
- How Flash Memory Changes the Five Minute Rule
- MySQL Manual and Guide
- High Performance MySQL, 3rd Edition By Baron Schwartz, Peter Zaitsev, Vadim Tkachenko
- Stat Tools and Database Related Articles - dimitrik
- About Sysbench on MySQL